Blog
The scaling problem behind the AI data center boom
If you could use just one word to encapsulate the challenges data center operators must solve as the AI era takes off, what would it be?
There’s no shortage to choose from: power, cooling, land, labor, capacity, returns, components, perception. And that’s the short list.
While access to power tops operators’ concerns, we’d argue that ramping capacity to meet current and future demand is not an ‘or’ problem — it’s an ‘and’ problem. So, we’re going to choose two words: scale and complexity.
It’s not a simple dichotomy, as there are hundreds of other nested ‘ands’ that must be assessed, balanced, and addressed on an ever-shifting basis. This market is moving faster than anything we’ve seen in decades. Moore’s Law has met its match in CPUs. Hyperscalers are inking funding, capacity, and infrastructure deals in a frenzy of coopetition. Companies in historically slower-growth industries are seeing valuations skyrocket as the demand for AI drives both innovation and growth.
That leads us to the data center infrastructure itself. On the scale side of the ‘and’ equation there are three axes happening at once, all with thorny, interconnected engineering problems to solve:
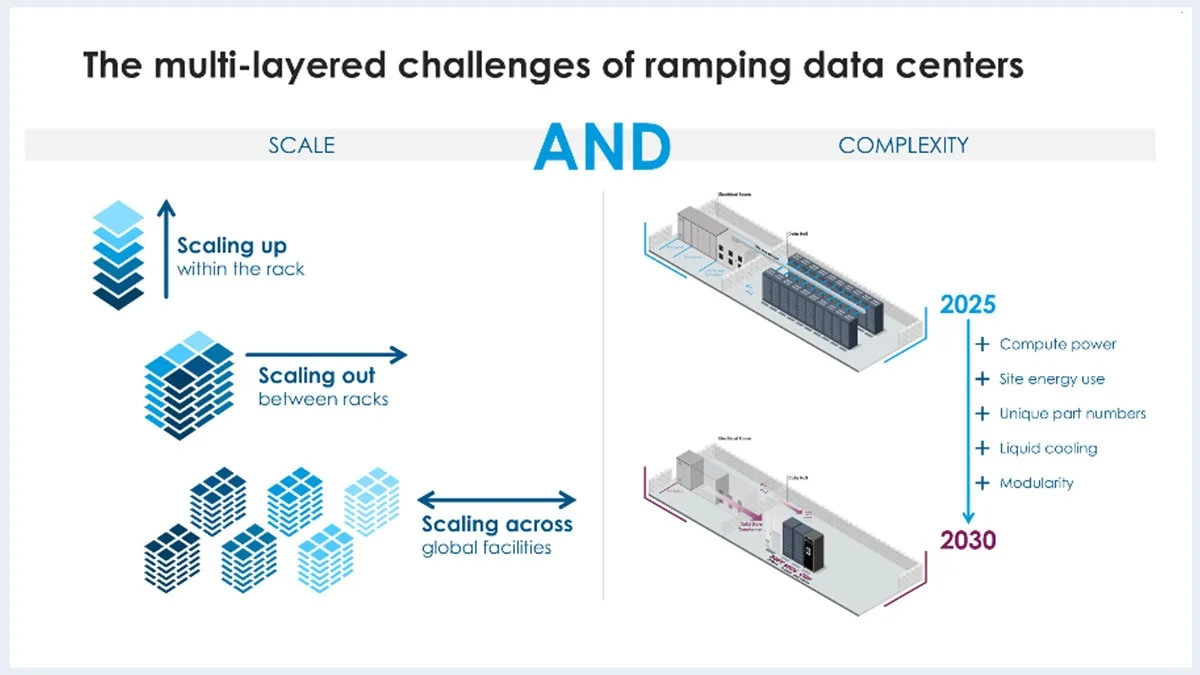
On the complexity side of the ‘and’ equation, scaling up, out, and across is happening at a rapid clip while compute power per rack, site energy use, unique component counts, and supply chain SKUs are increasing exponentially, too. That’s the core of the challenge — it’s not one hard thing; it’s many hard things happening all at once, all of them interconnected.
The first hidden risk is topological change. The physical architecture of a data center is undergoing a fundamental redesign, not an incremental evolution. And the pace of that redesign is faster than most organizations’ design cycles. Topology is changing most rapidly across three dimensions: power, cooling, and facility layout.
The industry is transitioning from 48 V rack power to 400 VDC and 800 VDC distribution. This isn’t a preference — it’s driven by physics. Higher voltage reduces the current required to deliver power to the rack (power = voltage x current), which translates into smaller copper conductors that significantly lower resistive losses. It also enables power conversion to be moved out of the IT rack and into external power shelves or sidecars. By relocating power conversion, the full volume within the rack can be dedicated to computing. At power densities approaching 1 megawatt per rack, this architecture isn’t optional.
The shift to higher voltages also drives a redesign of vertical power delivery architecture to minimize power delivery network (PDN) losses. Since those losses are concentrated near the load (the chips doing the computing), moving power conversion closer to the GPU instead of relying on long step-down paths can reduce energy drain.
At Flex, we’re shipping 400 VDC systems today and have 800 VDC systems entering deployment soon, with broad adoption expected by 2030.
Traditional air-based cooling systems are effective up to approximately 50 kW per rack. That is well below the power that AI workloads consume. The NVIDIA GB200 NVL72 is designed for approximately 120 kW at the rack level. Roadmaps across the ecosystem indicate that next-generation platforms will exceed 200 kW per rack. At these power densities, the associated heat cannot be removed efficiently with air. This makes liquid cooling, which is far more thermodynamically efficient than air cooling, a priority for every AI infrastructure deployment.
There are several technical approaches to liquid cooling, and they are not equivalent. Each has distinct operational implications. For instance, direct-to-chip cold plates are the most efficient for devices requiring high thermal design power (TDP). We’re delivering cold plate designs that can handle GPUs and accelerators exceeding 3,000 W TDP and 500 W/cm² thermal loads. Microconvective cold plate technology, which uses arrays of 800–900 localized fluid jets targeting hot spots at the die level, enables higher coolant temperatures — operating at or above 42°C inlet — which reduces or eliminates chiller requirements and dramatically lowers water consumption.
The Open Compute Project (OCP) and broader ecosystem have converged on flow rate targets of ~1.5 LPM/kW for liquid-cooled racks, up from roughly 1.0 LPM/kW ratings common in earlier generations. Rack-level CDUs are now designed to support 300 kW with flows approaching 400 LPM. At the row level, multi-rack CDU systems are already into the megawatt range, requiring several thousand LPM of coolant flows. These are the engineering parameters that define CDU design today.
The move to higher rack densities also alters how facilities are physically laid out. As rack height, weight, and spatial requirements diverge across deployments, structural considerations such as floor loading, networking pathways, and ceiling clearances must be reassessed. At the same time, the physical organization of the data hall is becoming less rigid, with layouts adapting to accommodate higher-density zones, varied equipment footprints, and new serviceability requirements.
To accommodate these changes and accelerate capacity buildout, the integration between mechanical, electrical, thermal, and firmware systems is starting to happen much earlier in the design cycle.
Data center operators are embracing modular designs that bridge the gap between AI-driven demand and traditional construction timelines.
One reason: on-site commissioning of complex liquid-cooled, high-voltage DC systems in a live data center is where schedule risk concentrates, and every commissioning delay on a program of this scale is expensive.
Prefabricated modular data center (PMDC) solutions are factory-built, pre-engineered units that enable scalable, predictable, and efficient capacity expansion. A factory-first approach that combines power and cooling in turnkey units improves performance predictability, simplifies installation, and allows module production and site work to proceed simultaneously. We’ve found that PMDC solutions can compress project schedules by 30 percent or more while significantly reducing the need for onsite labor. Additionally, onsite testing and cabling are reduced up to 70 percent when PMDC solutions are prewired and pretested at the factory, and changes in the field are minimized.
Construction and energization safety are also driving the adoption of PMDC solutions. When complex integration happens in the factory, they arrive on site with validated protections and interlocks. Integrated systems testing under simulated failures is completed before deployment, reducing risk to people, equipment, and facilities.
The demand curve for AI compute infrastructure is unlike anything the technology industry has faced before. Globally, demand for data center power has doubled in five years, and AI energy use is growing 4.5X. More than $1 trillion dollars in capital will be invested in data center expansion in 2026.
The race to scale AI data centers is real and urgent. The engineering problems are genuinely hard, not because the individual technologies don’t exist — they do — but because the rate of change across topology, market structure, and standards is faster than the industry’s ability to design, certify, and deploy in response to it.
The constraints everyone worries about — power, supply chains, sustainability — don’t go away. They compound. The organizations that succeed are the ones that coordinate across them instead of reacting to them one at a time. The answer isn’t a single technology, and it isn’t one company. It’s doing the work. For changing topologies, that means designing systems, not parts, and treating the rack and the data center as integrated architectures from day one.
Next time, we’ll take a closer look at a second and equally impactful hidden risk to data center build-out: market chaos.