
Blog
Understanding the medium-voltage bottleneck in AI expansion
Companies are recognizing AI as a competitive differentiator and use cases are proliferating. Powerful GPUs have captured imaginations and wallet share in the race to process extraordinary amounts of data faster. The technology is sensational, but what about the other hardware that makes AI computing possible?
If compute is the brain of the digital world, networking is the central nervous system — and it’s undergoing a significant transformation of its own. Welcome to the era of high-performance AI networking.
GPUs are very expensive, especially in the quantities required for large AI workloads. High performance, rack scale supercomputer platforms with 70-plus GPUs on board drive millions in capex. Enterprises and cloud providers investing heavily in advanced chipsets don’t want network bottlenecks to slow them down. What was once fine for business application data traveling at 25 gigabits per second (Gbps) is woefully inadequate at speeds approaching 1,600 Gbps (1.6 terabits per second), as is common during AI training. A high bandwidth, low latency AI network infrastructure is non-negotiable.
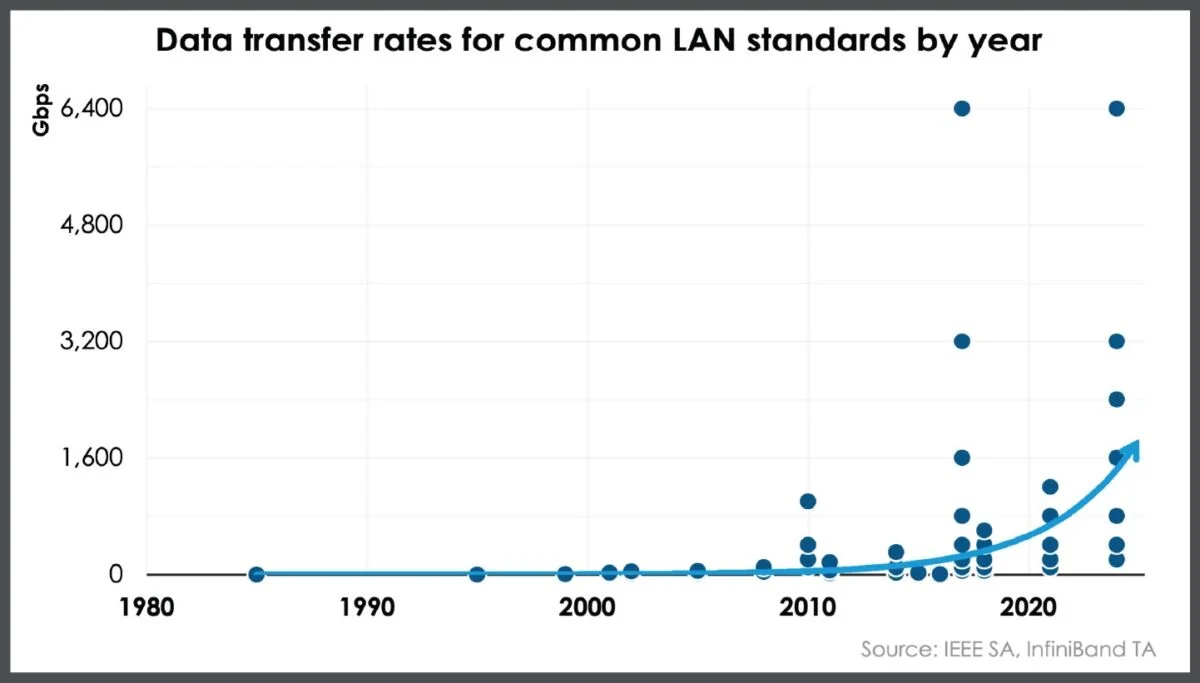
LAN data transfer rates have grown exponentially over the past decade, and some standards are expected to reach speeds of up to 25.6 Tbps in 2026, reinforcing the need for data center operators to ensure that they’re using the latest technologies to future-proof their sites.
Reducing network bottlenecks during AI data transfer between compute nodes has its challenges. Networking for AI is a three-prong problem: scaling up within the rack, scaling out between racks, and scaling across data center facilities when distributed AI networking is required due to space or power constraints.

The challenge in scaling up rests largely on connecting all of the GPUs in a rack with low latency, high bandwidth connections. Copper cable intra-rack networks are bandwidth constrained, and service providers are increasingly migrating these connections to fiber to minimize traffic jams and data loss, the parameters of which will evolve as GPUs do. Specialized AI interconnects may be required.

When hundreds of racks are connected in the data center, the challenge becomes managing congestion as multiple data flows compete for the same bandwidth. Advanced protocols enable least-point fabrics to optimize east-west AI traffic flow with networking switches, providing cost-optimized, high capacity, low latency links between GPUs.
When large AI workloads cannot be handled within a single data center, scale-across switches unify GPUs between multiple facilities so they can function as one. A high performance, geographically distributed AI fiber network infrastructure overcomes distance and data encryption challenges.
The rapid, synchronized movement of high volumes of data requires congestion-free AI networking fabrics, low-latency AI networking architectures and autonomous operations.
From a manufacturing standpoint, the takeaway is that data center operators must choose partners with the engineering expertise, production capabilities, and resilient supply chains to deliver sophisticated, high-quality AI networking components at scale. When unprecedented demand meets technological complexity and zero tolerance for performance issues, choosing wisely is essential.

Proven ability to manufacture complex, advanced data center technologies at the high volumes that hyperscalers, cloud providers, and colocation facility operators need to deliver on their compute capacity and performance mandates.

Deep knowledge of AI networking technologies paired with data center infrastructure expertise to help operators make holistic, well-informed decisions across multiple parameters, from bandwidth and latency considerations to power/cooling efficiency and deployment timelines.

Technicians at key manufacturing locations around the world with disciplined execution to meet SLAs and quality standards, who can handle complex AI networking assembly, intricate fiber routing, optical component integration, and more.

Design and engineering services with a focus on innovation, product excellence, and manufacturing readiness to minimize risk as production ramps up with increasing demand, and to understand how performance may vary over time.

Testing and validation services to help ensure product performance, reliability, and durability throughout the product lifecycle.

Advanced AI networking capabilities are a competitive differentiator for data center operators as AI workloads proliferate and substandard networks become a bottleneck. Unprecedented data traffic is driving innovation across AI network topologies to improve performance, security, and scalability.
To learn more about Flex’s role in deploying networking infrastructure for AI data centers, visit flex.com/industries/communications
What is networking for AI?
Networking for AI refers to the network architectures, systems, and technologies that connect GPUs and other IT hardware. They are designed to address the bandwidth, latency, throughput, and reliability demands of AI workloads.
How does networking for AI differ from traditional networking?
AI workloads can push data flows to terabits per second (Tbps), far exceeding legacy 25 Gbps/100 Gbps networks. To keep GPUs fully utilized, AI clusters require high bandwidth, lower latency, and lossless fabrics.
What does “scaling up, out, and across” mean in AI networking?
Scaling up: Increase per-GPU bandwidth inside the rack with strict signal integrity
Scaling out: Connect racks within a facility using congestion-aware fabrics
Scaling across: Unite GPUs across data centers using low-latency, encrypted fiber optic fabrics
What is a compute fabric in AI data centers?
A compute fabric is a high-speed, lossless network that enables multiple GPUs to operate as one. Fabrics are commonly designed to support 400 Gbps, 800 Gbps, and emerging 1.6 Tbps to 1.8 Tbps data flows.
How do SmartNICs and DPUs help AI workloads?
SmartNICs and DPUs offload storage, security, and data management tasks, freeing CPU cores for more intensive computing.
Why are optical interfaces important for AI clusters?
Co-packaged optics, silicon photonics, and linear pluggable optics place optics closer to GPUs and ASICs for better performance at scale.
What makes a switch “AI-optimized”?
AI-ready switches sustain bursty east-west traffic with advanced congestion control, adaptive routing, deep buffers (where appropriate), and intelligent power management.
When is liquid cooling needed in AI networking?
Liquid cooling is used when switch and AI accelerator densities push heat loads beyond the capabilities of air-cooling systems. It improves energy efficiency and thermal stability.
What is SONiC and why do data centers use it?
SONiC is an open-source network operating system that works with many different switch vendors, reducing product lock-in and simplifying large-scale AI network operations.
How should networking fabrics handle synchronized, bursty GPU traffic?
Use lossless or near-lossless design with congestion signaling, adaptive routing, and path diversity to prevent head-of-line blocking and keep GPU pipelines fed.
