
Blog
Den Mittelspannungsengpass bei der KI-Expansion verstehen
Unternehmen erkennen KI als Wettbewerbsvorteil, und die Anwendungsfälle nehmen rasant zu. Leistungsstarke GPUs haben die Fantasie und die Investitionen im Wettlauf um die immer schnellere Verarbeitung enormer Datenmengen beflügelt. Die Technologie ist sensationell, aber was ist mit der übrigen Hardware, die KI-Computing überhaupt erst ermöglicht?
Wenn die Rechenleistung das Gehirn der digitalen Welt ist, dann ist die Vernetzung das zentrale Nervensystem – und dieses durchläuft selbst einen tiefgreifenden Wandel. Willkommen im Zeitalter der leistungsstarken KI-Netzwerke.
GPUs sind sehr teuer, insbesondere in den Mengen, die für große KI-Workloads benötigt werden. Hochleistungsfähige Supercomputer-Plattformen im Rack-Format mit über 70 GPUs erfordern Investitionen in Millionenhöhe. Unternehmen und Cloud-Anbieter, die massiv in fortschrittliche Chipsätze investieren, wollen keine Netzwerkengpässe, die sie ausbremsen. Was früher für Geschäftsanwendungen mit Datenübertragungsraten von 25 Gigabit pro Sekunde (Gbit/s) ausreichend war, ist bei Geschwindigkeiten von fast 1.600 Gbit/s (1,6 Terabit pro Sekunde), wie sie beim KI-Training üblich sind, völlig unzureichend. Eine KI-Netzwerkinfrastruktur mit hoher Bandbreite und geringer Latenz ist daher unerlässlich.
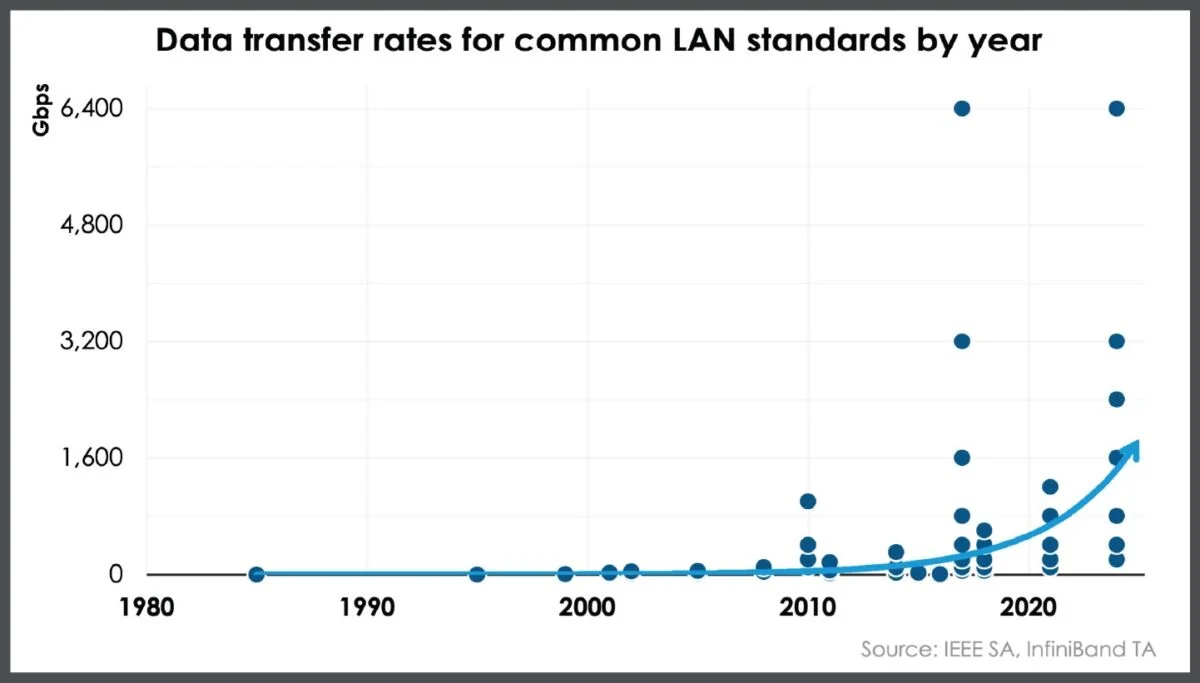
Die Datenübertragungsraten in LANs sind im letzten Jahrzehnt exponentiell gestiegen, und für einige Standards werden im Jahr 2026 Geschwindigkeiten von bis zu 25,6 Tbit/s erwartet. Dies unterstreicht die Notwendigkeit für Rechenzentrumsbetreiber, sicherzustellen, dass sie die neuesten Technologien einsetzen, um ihre Standorte zukunftssicher zu machen.
Die Reduzierung von Netzwerkengpässen beim KI-Datentransfer zwischen Rechenknoten birgt Herausforderungen. Die Vernetzung für KI ist ein dreifaches Problem: Skalierung innerhalb eines Racks, Skalierung zwischen Racks und Skalierung über Rechenzentrumseinrichtungen hinweg, wenn aufgrund von Platz- oder Energiebeschränkungen eine verteilte KI-Vernetzung erforderlich ist.

Die größte Herausforderung bei der Skalierung besteht darin, alle GPUs in einem Rack mit latenzarmen und bandbreitenstarken Verbindungen zu verbinden. Kupferkabel-Netzwerke innerhalb eines Racks stoßen an Bandbreitengrenzen, weshalb Serviceprovider diese Verbindungen zunehmend auf Glasfaser umstellen, um Engpässe und Datenverluste zu minimieren. Die genauen Parameter werden sich mit der Weiterentwicklung der GPUs verändern. Möglicherweise sind spezielle KI-Verbindungen erforderlich.

Wenn Hunderte von Racks in einem Rechenzentrum miteinander verbunden sind, besteht die Herausforderung darin, die Überlastung zu bewältigen, da mehrere Datenströme um dieselbe Bandbreite konkurrieren. Fortschrittliche Protokolle ermöglichen es Least-Point-Fabrics, den Ost-West-KI-Datenverkehr mit Netzwerk-Switches zu optimieren und so kostenoptimierte Verbindungen mit hoher Kapazität und geringer Latenz zwischen GPUs bereitzustellen.
Wenn große KI-Workloads nicht in einem einzelnen Rechenzentrum bewältigt werden können, vereinheitlichen Scale-Across-Switches die GPUs mehrerer Standorte, sodass diese wie ein einziges System funktionieren. Eine leistungsstarke, geografisch verteilte KI-Glasfasernetzwerkinfrastruktur überwindet Herausforderungen hinsichtlich Entfernung und Datenverschlüsselung.
Die schnelle, synchronisierte Übertragung großer Datenmengen erfordert staufreie KI-Netzwerkstrukturen, KI-Netzwerkarchitekturen mit geringer Latenz und autonome Abläufe.
Aus Sicht der Fertigung lässt sich festhalten, dass Rechenzentrumsbetreiber wählen müssen Partner mit technischem Know-how, Produktionskapazitäten und widerstandsfähigen Lieferketten Um anspruchsvolle, hochwertige KI-Netzwerkkomponenten in großem Umfang bereitzustellen. Angesichts der beispiellosen Nachfrage, der technologischen Komplexität und der Nulltoleranz gegenüber Leistungsproblemen ist eine kluge Auswahl unerlässlich.

Nachgewiesene Fähigkeit zu Herstellung komplexer, fortschrittlicher Rechenzentrumstechnologien bei den hohen Datenmengen, die Hyperscaler, Cloud-Anbieter und Betreiber von Colocation-Einrichtungen benötigen, um ihre Anforderungen an Rechenkapazität und Leistung zu erfüllen.

Tiefgreifende Kenntnisse von KI-Netzwerktechnologien gepaart mit Expertise im Bereich Rechenzentrumsinfrastruktur um Betreibern zu helfen, ganzheitliche und fundierte Entscheidungen unter Berücksichtigung verschiedener Parameter zu treffen, von Bandbreiten- und Latenzüberlegungen bis hin zu Energie-/Kühlungseffizienz und Bereitstellungszeitplänen.

Techniker bei wichtige Produktionsstandorte weltweit mit disziplinierter Ausführung zur Einhaltung von SLAs und Qualitätsstandards, die in der Lage sind, komplexe KI-Netzwerkmontagen, komplizierte Glasfaserverlegung, die Integration optischer Komponenten und mehr zu bewältigen.

Design- und Ingenieurdienstleistungen mit Fokus auf Innovation, Produktqualität und Produktionsbereitschaft, um Risiken bei Produktionssteigerungen aufgrund steigender Nachfrage zu minimieren und zu verstehen, wie sich die Leistung im Laufe der Zeit verändern kann.

Test- und Validierungsdienste um die Leistungsfähigkeit, Zuverlässigkeit und Langlebigkeit des Produkts während des gesamten Produktlebenszyklus zu gewährleisten.

Fortschrittliche KI-Netzwerkfunktionen sind für Rechenzentrumsbetreiber ein entscheidender Wettbewerbsvorteil, da KI-Workloads immer häufiger eingesetzt werden und unzureichende Netzwerke zum Engpass werden. Beispielloses Datenaufkommen treibt Innovationen in den gesamten KI-Netzwerktopologien voran, um Leistung, Sicherheit und Skalierbarkeit zu verbessern.
Um mehr über die Rolle von Flex beim Aufbau der Netzwerkinfrastruktur für KI-Rechenzentren zu erfahren, besuchen Sie flex.com/industries/communications
Was ist Vernetzung für KI?
Die Vernetzung für KI bezieht sich auf die Netzwerkarchitekturen, Systeme und Technologien, die GPUs und andere IT-Hardware verbinden. Sie sind darauf ausgelegt, die Anforderungen von KI-Workloads hinsichtlich Bandbreite, Latenz, Durchsatz und Zuverlässigkeit zu erfüllen.
Wie unterscheidet sich die Vernetzung für KI von der traditionellen Vernetzung?
KI-Workloads können Datenströme im Terabit-Bereich (Tbps) erzeugen und damit die Kapazität herkömmlicher 25-Gbit/s-/100-Gbit/s-Netzwerke deutlich übertreffen. Um die GPUs optimal auszulasten, benötigen KI-Cluster hohe Bandbreite, geringe Latenz und verlustfreie Netzwerkarchitekturen.
Was bedeutet “Skalierung nach oben, außen und quer” im Kontext von KI-Netzwerken?
Skalierung: Erhöhung der Bandbreite pro GPU innerhalb des Racks bei strikter Signalintegrität
Skalierung nach außen: Verbinden Sie Racks innerhalb einer Anlage mithilfe von kapazitätsoptimierten Fabrics.
Skalierung über verschiedene Bereiche hinweg: GPUs in Rechenzentren mithilfe latenzarmer, verschlüsselter Glasfaserverbindungen vereinen.
Was ist eine Compute Fabric in KI-Rechenzentren?
Ein Compute Fabric ist ein Hochgeschwindigkeitsnetzwerk mit verlustfreier Übertragung, das es mehreren GPUs ermöglicht, wie eine einzige GPU zu arbeiten. Solche Fabrics sind üblicherweise für Datenraten von 400 Gbit/s, 800 Gbit/s und den aufkommenden Datenraten von 1,6 Tbit/s bis 1,8 Tbit/s ausgelegt.
Wie unterstützen SmartNICs und DPUs KI-Workloads?
SmartNICs und DPUs entlasten die Speicher-, Sicherheits- und Datenverwaltungsaufgaben und geben so CPU-Kerne für rechenintensivere Aufgaben frei.
Warum sind optische Schnittstellen für KI-Cluster wichtig?
Durch die Integration von Optiken in Gehäuse, Siliziumphotonik und linearen steckbaren Optiken rücken optische Bauteile näher an GPUs und ASICs heran, was zu einer besseren Leistung im großen Maßstab führt.
Was macht einen Schalter “KI-optimiert”?
KI-fähige Switches bewältigen sprunghafte Ost-West-Verkehrsspitzen dank fortschrittlicher Staukontrolle, adaptivem Routing, großen Puffern (wo angebracht) und intelligentem Energiemanagement.
Wann ist Flüssigkeitskühlung in KI-Netzwerken erforderlich?
Flüssigkeitskühlung kommt zum Einsatz, wenn die Dichte von Schaltern und KI-Beschleunigern die Wärmelasten über die Kapazität von Luftkühlsystemen hinaus erhöht. Sie verbessert die Energieeffizienz und die thermische Stabilität.
Was ist SONiC und warum wird es in Rechenzentren eingesetzt?
SONiC ist ein Open-Source-Netzwerkbetriebssystem, das mit vielen verschiedenen Switch-Herstellern zusammenarbeitet, die Produktabhängigkeit verringert und den Betrieb von KI-Netzwerken im großen Maßstab vereinfacht.
Wie sollten Netzwerkarchitekturen mit synchronisiertem, stoßartigem GPU-Datenverkehr umgehen?
Um Blockierungen am Anfang der Pipeline zu verhindern und die GPU-Pipelines auszulasten, sollten verlustfreie oder nahezu verlustfreie Designs mit Stauerkennung, adaptivem Routing und Pfaddiversität eingesetzt werden.
